

План семантического веба
- Вступление
- Подтверждение доказательства - язык для подтверждения
- Эволюция правил Язык
- Языки запросов
- Указатели терминов
Тим Бернерс-Ли
Дата: сентябрь 1998 года. Дата последнего изменения: $ Дата: 1998/10/14 20:17:13 $
Статус: попытка дать высокоуровневый план архитектуры Semantic WWW. Статус редактирования: Черновик. Комментарии приветствуются
До вопросов дизайна
Дорожная карта на будущее, архитектурный план, не проверенный ничем, кроме мысленных экспериментов.
Это было написано как часть запрошенной дорожной карты для будущего веб-дизайна, начиная с уровня 20 000 футов. Он был выделен из архитектурного обзора для области, которая требовала большей проработки, чем этот обзор мог себе позволить.
Обязательно, от 20 000 футов, большие вещи, кажется, получают небольшое упоминание. Таким образом, это архитектура в том смысле, что, как мы надеемся, все будет сочетаться друг с другом. Поэтому мы должны признать, что, хотя это может медленно меняться, это также живой документ.
Этот документ представляет собой план для создания набора связанных приложений для данных в Интернете таким образом, чтобы сформировать согласованную логическую сеть данных (семантическая сеть).
Вступление
Сеть была спроектирована как информационное пространство с целью, чтобы она была полезна не только для общения между людьми, но и для того, чтобы машины могли участвовать и помогать. Одним из основных препятствий для этого является тот факт, что большая часть информации в Интернете предназначена для потребления человеком, и даже если она была получена из базы данных с четко определенными значениями (по крайней мере, в некоторых терминах) для ее столбцов, что структура данных не видно для робота, просматривающего Интернет. Оставляя в стороне проблему искусственного интеллекта, состоящую в том, чтобы обучать машины вести себя как люди, подход Semantic Web вместо этого развивает языки для выражения информации в обрабатываемой машиной форме.
В этом документе дается «дорожная карта» - последовательность постепенного внедрения технологии, которая шаг за шагом выводит нас из современной сети в сеть, в которой машинное мышление будет повсеместным и невероятно мощным.
Следует примечание на архитектура сети, которая определяет существующие дизайнерские решения и принципы для того, что было достигнуто до настоящего времени.
Семантическая паутина - это сеть данных, в некотором смысле похожая на глобальную базу данных. Обоснование создания такой инфраструктуры дано в другом месте [Web будущего и т. Д.], Здесь я только обрисовываю архитектуру такой, какой я ее вижу.
При рассмотрении возможной формулировки универсальной сети семантических утверждений принцип минималистического дизайна требует, чтобы он основывался на общей модели большой общности. Только когда общая модель является общей, любое потенциальное приложение может быть отображено на модель. Общая модель - это структура описания ресурсов.
Увидеть Модель RDF и спецификация синтаксиса
Быть общим, это очень просто. Проще говоря, вы ничего не можете сделать с самой моделью, не разбирая много вещей сверху. Базовая модель содержит только концепцию утверждения и концепцию цитаты - создание утверждений об утверждениях. Это введено потому, что (а) оно все равно понадобится позже и (б) большинство исходных приложений RDF предназначены для данных о данных («метаданных»), в которых утверждения об утверждениях являются базовыми, даже до логики. (Поскольку для целевых приложений RDF утверждения являются частью описания какого-либо ресурса, этот ресурс часто является неявным параметром, а утверждение известно как свойство ресурса).
Что касается математики, язык на этом этапе не имеет отрицания или смысла, и поэтому очень ограничен. Учитывая набор фактов, легко сказать, существует ли доказательство для какого-либо конкретного вопроса, потому что ни факты, ни вопросы не могут иметь достаточной силы, чтобы сделать проблему неразрешимой.
Заявки на этом уровне очень многочисленны. Большинство из приложения для представления метаданных может быть обработано RDF на этом уровне. Примерами могут служить данные картотеки (Dublin Core), информация о конфиденциальности (P3P), ассоциации таблиц стилей с документами, маркировка прав интеллектуальной собственности и метки PICS. Мы говорим о представлении данных здесь, что обычно просто: не языки для выражения запросов или правил вывода.
Документы RDF на этом уровне не обладают большой силой, и иногда становится менее очевидным, почему нужно связывать приложение в RDF. Ответ заключается в том, что мы ожидаем, что эти данные, хотя и ограниченные и простые в приложении, впоследствии будут объединены с данными из других приложений в Web. Приложения, работающие по всей сети, должны иметь возможность использовать общую среду для объединения информации из всех этих приложений. Например, логика управления доступом может использовать комбинацию конфиденциальности и членства в группах, а также информацию о типе данных, чтобы фактически разрешить или запретить доступ. Позднее запросы могут разрешать мощные логические выражения, относящиеся к данным из доменов, в которых язык представления данных по отдельности не очень выразителен. Цель этого документа частично показать план, по которому это может произойти.
Базовая модель RDF позволяет нам многое делать на доске, но не дает нам много инструментов. Это дает нам модель утверждений и цитат, по которым мы можем отобразить данные в любом новом формате.
Затем нам понадобится слой схемы, чтобы объявить о существовании нового свойства. Нам нужно в то же время сказать немного больше об этом. Мы хотим быть в состоянии ограничить использование. Обычно мы хотим ограничить типы объектов, к которым он может применяться. Эти мета-утверждения позволяют выполнять элементарные проверки документа. Как и в SGML, «DTD» позволяет проверить, использовались ли элементы в соответствующих позициях, поэтому в RDF схема позволит нам проверить, например, что водительские права имеют имя человека, а не модель автомобиля, как его "имя".
Мне не ясно, какие именно примитивы нужно вводить, и можно ли определить много полезного языка на этом уровне, не определяя при этом следующий уровень. Там в настоящее время RDF Схема рабочая группа в этой области. Язык схемы обычно делает простые утверждения о разрешенных комбинациях. Если SGML DTD используется в качестве модели, схема может быть на языке с очень ограниченными возможностями. Ограничения, выраженные на языке схемы, легко расширяются до более мощных выражений логического уровня (следующего уровня), но один из них выбран на этом этапе, чтобы ограничить возможности, а не делать это. Например: в схеме можно сказать, что свойство foo уникально. Это означает, что для любого x, если y - это foo из x, а z - это foo из x, то y равно z. При этом используются логические выражения, которые недоступны на этом уровне, но это нормально, если на данный момент язык схемы будет обрабатываться только специализированными механизмами схем, а не механизмом общих рассуждений.
Когда мы делаем такие вещи с языком - и я думаю, что это будет очень распространено - мы должны быть осторожны, чтобы язык все еще был хорошо определен логически. Позже мы можем захотеть сделать выводы, которые могут быть сделаны только путем понимания семантики языка схемы в логических терминах и объединения ее с другой логической информацией.
Требование работы пространств имен для evolvability заключается в том, что со знанием общих RDF на каком-то уровне нужно уметь следовать правилам преобразования документа в одной RDF-схеме в другую (что, по-видимому, обладает врожденным пониманием того, как обрабатывать).
По принципу наименьшей силы этот язык может фактически иметь смысл (правила вывода) без отрицания. (Это может показаться тонким замечанием, когда на самом деле можно легко написать правило, которое определяет вывод из оператора A другого оператора B, который на самом деле оказывается ложным, даже если в языке нет способа фактически указать «False» Тем не менее формально язык не обладает способностью писать парадокс, который утешает некоторых людей. В дальнейшем, хотя язык становится более выразительным, мы полагаемся не на врожденную способность делать парадоксальные утверждения, а на приложения, конкретно ограничивающие выразительную силу конкретных документов. Схемы предоставляют удобное место для описания этих ограничений.)
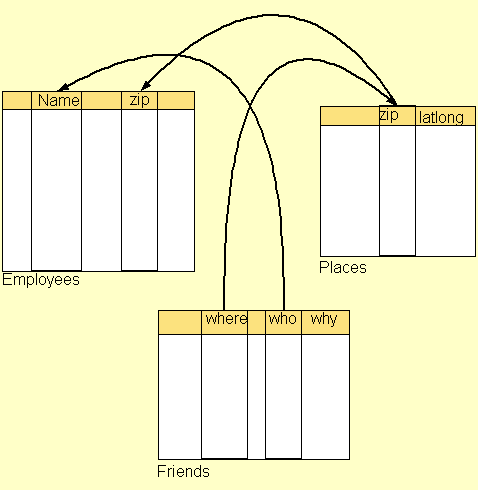 Простой пример применения этого уровня - это когда две базы данных, созданные независимо, а затем размещенные в сети, связаны семантическими ссылками, которые позволяют преобразовывать запросы в одной в запросы в другой. Здесь кто-то заметил, что «где» в таблице друзей и «zip» в таблице мест означают одно и то же. Кто-то еще задокументировал, что «zip» в таблице мест означало то же, что и «zip» в таблице сотрудников и т. Д., Как показано стрелками. Учитывая эту информацию, поиск любого сотрудника по имени Фред с почтовым индексом 02139 может быть расширен среди сотрудников, включая друзей . Все, что нужно RDF - это «эквивалентное» свойство.
Простой пример применения этого уровня - это когда две базы данных, созданные независимо, а затем размещенные в сети, связаны семантическими ссылками, которые позволяют преобразовывать запросы в одной в запросы в другой. Здесь кто-то заметил, что «где» в таблице друзей и «zip» в таблице мест означают одно и то же. Кто-то еще задокументировал, что «zip» в таблице мест означало то же, что и «zip» в таблице сотрудников и т. Д., Как показано стрелками. Учитывая эту информацию, поиск любого сотрудника по имени Фред с почтовым индексом 02139 может быть расширен среди сотрудников, включая друзей . Все, что нужно RDF - это «эквивалентное» свойство.
Следующий уровень, то есть логический уровень. Нам нужны способы записи логики в документы, чтобы разрешить такие вещи, как, например, правила вычитания одного типа документа из документа другого типа; проверка документа на соответствие правилам самосогласованности; и разрешение запроса путем преобразования неизвестных терминов в известные термины. Учитывая, что у нас уже есть цитата на языке, следующий уровень - это логика предикатов (не, и т. Д.) И квантификация следующего уровня (для всех x, y (x)).
Применение RDF на этом уровне в основном ограничено только воображением. Простой пример применения этого уровня - это когда две базы данных, созданные независимо, а затем размещенные в сети, связаны семантическими ссылками, которые позволяют преобразовывать запросы в одной в запросы в другой. Многие вещи, которые, возможно, нуждались в новом языке, внезапно стали просто вопросом написания правильного RDF. Если у вас есть язык, обладающий огромной силой исчисления предикатов с кавычками, то при определении нового языка для конкретного приложения требуются две вещи:
- Необходимо установить (ограниченную) мощность механизма рассуждения, которым должен обладать получатель, и определить подмножество полного RDF, которое, как ожидается, будет понято;
- Возможно, вы захотите определить некоторые сокращенные функции для эффективной передачи выражений в наборе документов на ограниченном языке.
Смотрите также, если не уверены:
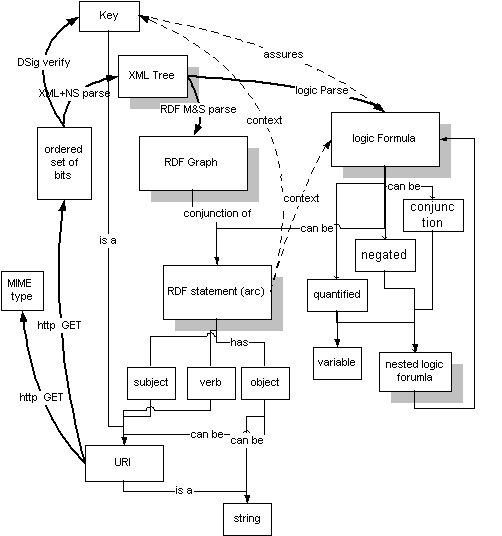
Карта метро ниже показывает ключевую петлю в семантической сети. Веб-часть слева показывает, как URI, используя HTTP, превращается в представление документа в виде строки битов с некоторым типом MIME. Затем он анализируется в XML, а затем в RDF, чтобы получить граф RDF или, на логическом уровне, логическую формулу. С правой стороны, Семантическая часть, показывает, как граф RDF содержит ссылку на URI. Это доверие от ключа в сочетании со значением операторов, содержащихся в документе, которое может привести к тому, что движок семантической паутины разыменует другой URI.
Подтверждение доказательства - язык для подтверждения
Модель RDF ничего не говорит о форме механизма рассуждений, и это, очевидно, открытый вопрос, поскольку не существует абсолютно совершенного алгоритма для ответа на вопросы - или, в основном, для поиска доказательств. Однако на данном этапе разработки семантической паутины мы не решаем эту проблему. В большинстве приложений построение доказательства выполняется в соответствии с некоторыми довольно ограниченными правилами, и все, что нужно сделать другой стороне, это проверить общее доказательство. Это тривиально.
Например, когда кому-то предоставляется доступ к веб-сайту, ему может быть предоставлен документ, который объясняет веб-серверу, почему он должен иметь доступ. Доказательством будет цепочка [ну, DAG] утверждений и правил рассуждений с указателями на весь вспомогательный материал.
То же самое относится и к транзакциям, связанным с конфиденциальностью, и большей части электронной коммерции. Документы, отправленные через сеть, будут написаны на полном языке. Тем не менее, они будут ограничены, так что, если запросы, результаты будут вычислимы, и в большинстве случаев они будут доказательствами. HTTP «GET» будет содержать доказательство того, что клиент имеет право на ответ. ответ будет доказательством того, что ответ на самом деле является тем, о чем просили.
Эволюция правил Язык
RDF на логическом уровне уже имеет право выражать правила вывода. Например, вы должны быть в состоянии сказать такие вещи, как «Если почтовый индекс организации x равен y, то рабочий код почтового индекса x равен y». Как отмечалось выше, рассеяние в Интернете с такими замечаниями в конечном итоге будет очень интересным, но в краткосрочной перспективе не даст повторяемых результатов, если мы не ограничим выразительность документов для решения конкретных задач приложения.
Две фундаментальные функции, которые нам нужны для работы RDF-движков:
- чтобы реализация версии n была в состоянии прочитать достаточно схемы RDF, чтобы иметь возможность определить, как читать документ версии n + 1 ;
- для приложения типа A, разработанного совершенно независимо от приложения типа B, которое имеет такую же или аналогичную функцию, чтобы иметь возможность считывать и обрабатывать достаточно информации о схеме, чтобы иметь возможность обрабатывать данные из приложения типа B.
(Увидеть статья о эволюционируемости )
Логический уровень RDF достаточен для использования в качестве языка для создания правил вывода. Обратите внимание, что это не касается эвристики какого-либо конкретного механизма рассуждений, который является открытым полем, сделанным Семантической сетью еще более открытым и плодотворным. Другими словами, RDF позволит вам писать правила, но никому не скажет на данном этапе, в каком порядке их применять.
Если, например, схема библиотеки конгресса говорит об «авторе», а Британская библиотека говорит о «создателе», то небольшая часть RDF могла бы сказать, что для любого человека x и любого ресурса y, если x - это (LoC) автор y, тогда x - (BL) создатель y. Это своего рода правило, которое решает проблемы эволюционируемости. Где бы процессор нашел его? В случае программы, которая находит документ версии 2 и хочет найти правила для преобразования его в документ версии 1, тогда схема версии 2, естественно, будет содержать или указывать на правила. В случае ретроспективного документирования отношений между двумя независимо придуманными схемами, конечно, указатели на правила могут быть добавлены к любой схеме, но если это не является (социально) практичным, то у нас есть другой пример проблемы аннотации. Это можно решить с помощью сторонних индексов, в которых можно искать соединения между двумя схемами. На практике, конечно, поисковые системы предоставляют эту функцию очень эффективно - вам просто нужно запросить в поисковой системе все ссылки на одну схему и проверить результаты на наличие правил, которые нравятся двум.
Языки запросов
Одним из них является язык запросов. Запрос можно рассматривать как утверждение о возвращаемом результате. По сути, RDF на логическом уровне достаточно, чтобы представить это в любом случае. Однако на практике механизм запросов имеет специальные алгоритмы и индексы, с которыми можно работать, и поэтому может отвечать на конкретные запросы.
Конечно, на практике это может развить словарный запас, который помогает одним из двух способов:
- Это позволяет кратко выразить общие мощные типы запросов с меньшим количеством страниц математики, или
- Это позволяет выражать определенные ограниченные запросы, которые интересны тем, что имеют определенные свойства вычислимости.
SQL является примером языка, который делает и то, и другое.
Очевидно, что язык запросов должен быть определен в терминах логики RDF. Например, чтобы запросить у сервера информацию об авторе ресурса, можно запросить утверждение вида «x является автором p1» для некоторого x. Чтобы запросить окончательный список всех авторов, можно было бы запросить набор авторов, чтобы любой автор был в наборе, а каждый в наборе был автором. И так далее.
На практике разнообразие алгоритмов в поисковых системах в Интернете и алгоритмов поиска в логических системах, предшествующих сети, позволяет предположить, что в семантической сети будет много форм агентов, способных дать ответы на различные формы запросов.
Один полезный шаг - спецификация конкретных механизмов запросов, например, для поиска на конечном уровне глубины в указанном подмножестве Интернета (например, на веб-сайте). Конечно, может быть несколько альтернатив для разных случаев.
Другой метастеп - это спецификация языка описания механизма запросов - в основном, спецификация вида запроса, который механизм может возвращать в общем виде. Это откроет дверь агентам, объединяющим поиски и выводы во многих промежуточных двигателях.
Криптография с открытым ключом - замечательная технология, которая полностью меняет то, что возможно. В то время как можно добавить блок цифровой подписи в качестве украшения для существующего документа, попытки добавить логику доверия, как обледенение системы рассуждений, до настоящего времени были ограничены системами, ограниченными в своей общности. Чтобы рассуждать, чтобы иметь возможность принимать во внимание доверие, общая логическая модель требует расширения, чтобы включать ключи, с которыми были подписаны утверждения.
Как и вся логика, основа этого может поначалу не показаться привлекательной, пока не увидишь, что можно построить на вершине. Эта основа - введение ключей как объектов первого класса (где URI может быть буквальным значением открытого ключа) и введение общих рассуждений об утверждениях, относящихся к ключам.
В реализации это означает, что механизм рассуждений должен быть привязан к системе проверки подписи. Документы будут разбираться не только на деревья утверждений, но и на деревья утверждений о том, кто подписал какие утверждения. Проверка правильности, для правил вывода, проверит логику, но для утверждений, что документ был подписан, проверит подпись.
Результатом будет система, которая может выражать и рассуждать о взаимоотношениях по всему спектру систем безопасности и доверия на основе открытых ключей.
Цифровая подпись становится интересной, когда RDF развит до уровня, на котором существует язык доказательства. Тем не менее, он может быть разработан параллельно с RDF по большей части.
В W3C ввод в работу по цифровой подписи происходит из многих направлений, включая опыт работы с подписанными надписями «pics» DSig1.0 и различные представления для документов с цифровой подписью.
Указатели терминов
Учитывая всемирную семантическую сеть утверждений, технология поисковых систем, применяемая в настоящее время (1998) к страницам HTML, предположительно будет переводиться непосредственно в индексы не слов, а объектов RDF. Это само по себе позволит гораздо более эффективный поиск в Интернете, как если бы это была одна гигантская база данных, а не одна гигантская книга.
В настоящее время удовлетворены требования к переводу с версии A на версию B, и поэтому, когда существуют две базы данных, например, большие массивы (возможно, виртуальные) RDF-файлов, тогда даже если исходные схемы могут не совпадать, ретроспективная документация их эквивалентность позволила бы поисковой системе удовлетворять запросы путем поиска в обеих базах данных.
В то время как поисковые системы, которые индексируют HTML-страницы, находят много ответов на запросы и охватывают огромную часть Интернета, затем возвращают много неуместных ответов. В таких поисках нет понятия «правильности». Напротив, логические движки, как правило, были в состоянии ограничить свой вывод тем, что является доказуемо правильным ответом, но страдали от неспособности порыться в массе переплетенных данных для построения правильных ответов. Комбинаторный взрыв прослеживаемых возможностей был довольно трудноразрешимым.
Тем не менее, масштаб, в котором поисковые системы были успешными, может заставить нас пересмотреть наши предположения здесь. Если механизм будущего объединяет механизм рассуждений с поисковым механизмом, он может получить лучшее из обоих миров и реально построить доказательства в определенном числе случаев очень реального воздействия. Он сможет обращаться к индексам, которые содержат очень полные списки всех вхождений данного термина, а затем использовать логику, чтобы отсеять все, кроме тех, которые могут быть полезны при решении данной проблемы.
Таким образом, хотя ничто не заставит комбинаторный взрыв исчезнуть, многие проблемы реальной жизни могут быть решены с помощью всего лишь нескольких (скажем, двух) шагов вывода в «дикой паутине», а остальная часть рассуждений находится в области, в которой приводятся доказательства. или есть ограничения и хорошо понятные вычислимые алгоритмы. Я также ожидаю получить коммерческий стимул для разработки механизмов и алгоритмов, которые будут эффективно решать конкретные типы проблем. Это может включать создание кэшей промежуточных результатов, очень похожих на индексы поисковых систем сегодня.
Хотя по-прежнему не будет машины, которая может гарантировать ответ на произвольные вопросы, способность отвечать на реальные вопросы, которые являются предметом нашей повседневной жизни и особенно в сфере торговли, может быть весьма примечательной.
В этой серии:
Язык представления CYC
Формат обмена знаниями (KIF)
@@
Подтверждения
Этот план основан на обсуждениях с командой W3C и различными компаниями-членами W3C. Спасибо также Дэвиду Каргеру и Дэниелу Джексону из MIT / LCS.
До вопросов дизайна
Похожие
Создайте классы запросов и ответов с привязками JAXB... язык описания веб-служб) представляют собой XML, и несколько методов легко доступны для привязки XML к объекту. JAXB Java Architecture for XML Binding - это признанная технология для связывания. Другие способы связывания классов Java с XML включают АБР Привязка данных оси 2 и XML Beans Создание дорожной карты: руководство по началу работы
Если вы готовы начать создавать дорожную карту, я предполагаю две вещи. Во-первых, ваша организация уже определила видение вашего продукта - ваш общий план того, что продукт будет достигать на рынке и для вашей компании. Во-вторых, вы и ваша команда определили стратегию высокого уровня, чтобы Вступление Apache и Nginx - два популярных веб-сервера с открытым исходным кодом, которые часто используются...
Вступление Apache и Nginx - два популярных веб-сервера с открытым исходным кодом, которые часто используются с PHP. Может быть полезно запускать их оба на одной виртуальной машине при размещении нескольких веб-сайтов с различными требованиями. Общее решение для запуска двух веб-серверов в одной системе заключается в использовании нескольких IP-адресов или разных номеров портов. Капли, имеющие адреса как IPv4, так и IPv6, можно настроить для обслуживания сайтов Apache Где бы процессор нашел его?






